AI下沉,Arm的“硬”普及与“软”开放
更新时间:2019-10-30
链料网·找料的现货平台
当以5G、IoT、AI等作为主要驱动力的第五波浪潮(fifth wave)来袭时,计算领域的发展重新构建了我们的生活。
一直以来,大量的数据从边缘流向云端,但随着数据和设备的数量呈指数型增长,把所有数据都放到云端处理变得越来越不现实,更不用说安全和成本效益。
机器学习(Machine Learning,ML)向“边缘”转移成为必然趋势,它将助力AI在更大范围的普及,推进更为多元化的应用。从整体架构来看,只有提升边缘的智能性,才能解决带宽、功耗、成本、延时、可靠性和安全性等多方面问题。

由于消费级设备越来越智能化,通过专属的ML处理器提供额外的AI性能与效率非常有必要。
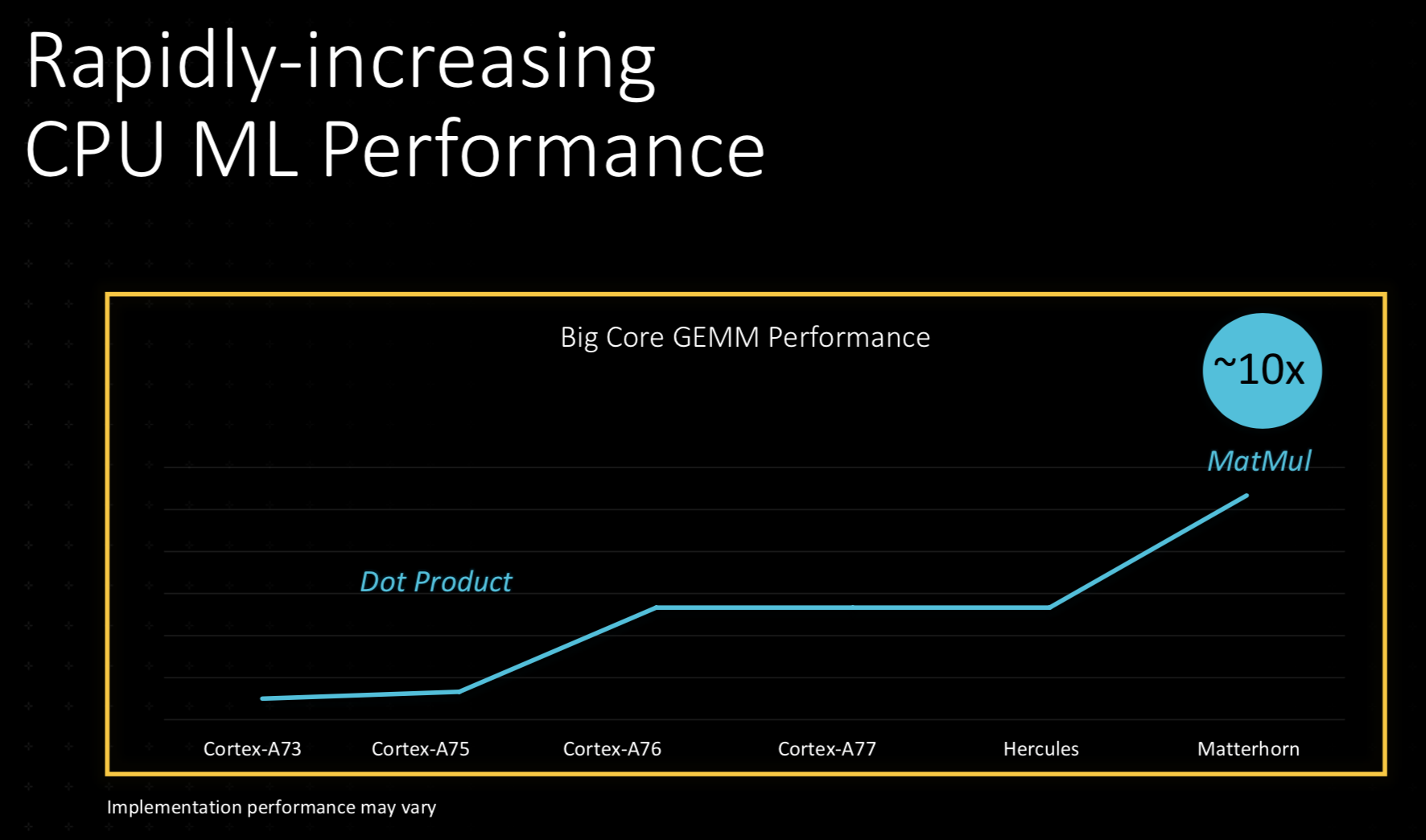
自从推出Cortex-A73后,Arm便逐步且逐代地提升性能,大幅拓宽针对ML的CPU覆盖。计算能力不断被推升至全新水平,直到最新一代Matterhorn内核,预计其计算性能将提升10倍。
当CPU和GPU面对边缘计算更密集计算、更复杂任务、更高效需求等显现出一定的匮乏时,NPU将派上用场。
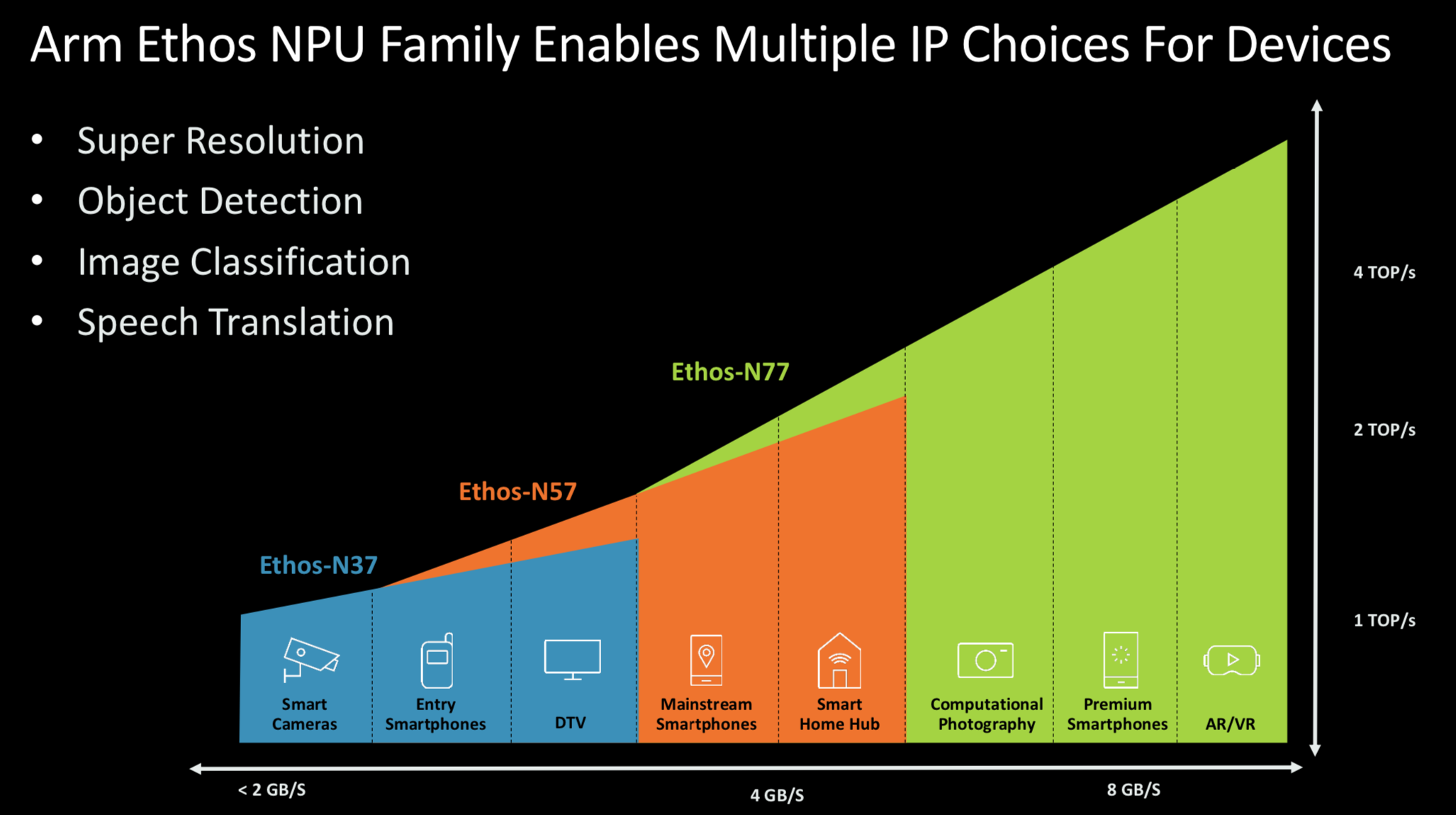
继定位于高端设备的Ethos-N77发布后,此次,Ethos NPU家族又添Ethos-N57与Ethos-N37两位新成员,将ML处理器延伸到主流市场。全新的Ethos对成本与电池寿命最为敏感的设计进行了优化,可以为日常生活设备带来优质的AI体验。
Ethos-N57与Ethos-N37的设计理念包括:
针对Int8与Int16数据类型的支持性进行优化;
先进的数据管理技术,以减少数据的移动与相关的耗电;
通过如创新的Winograd技术的落地,使性能比其他NPU提升超过200%。
Ethos-N57旨在提供平衡的ML性能与功耗效率,能够针对每秒2兆次运算次数的性能范围进行优化;Ethos-N37则为了提供面积最小的ML推理处理器(小于1平方毫米)而设计,能够针对每秒1兆次运算次数的性能范围进行优化。

Arm在ML内核方面主要关注数据管理,在设计中更多地注入了智能数据管理的功能和理念,例如数据敏感型的压缩技术、高密度剪枝和稀疏功能等。
Mali-G57关键功能包括:
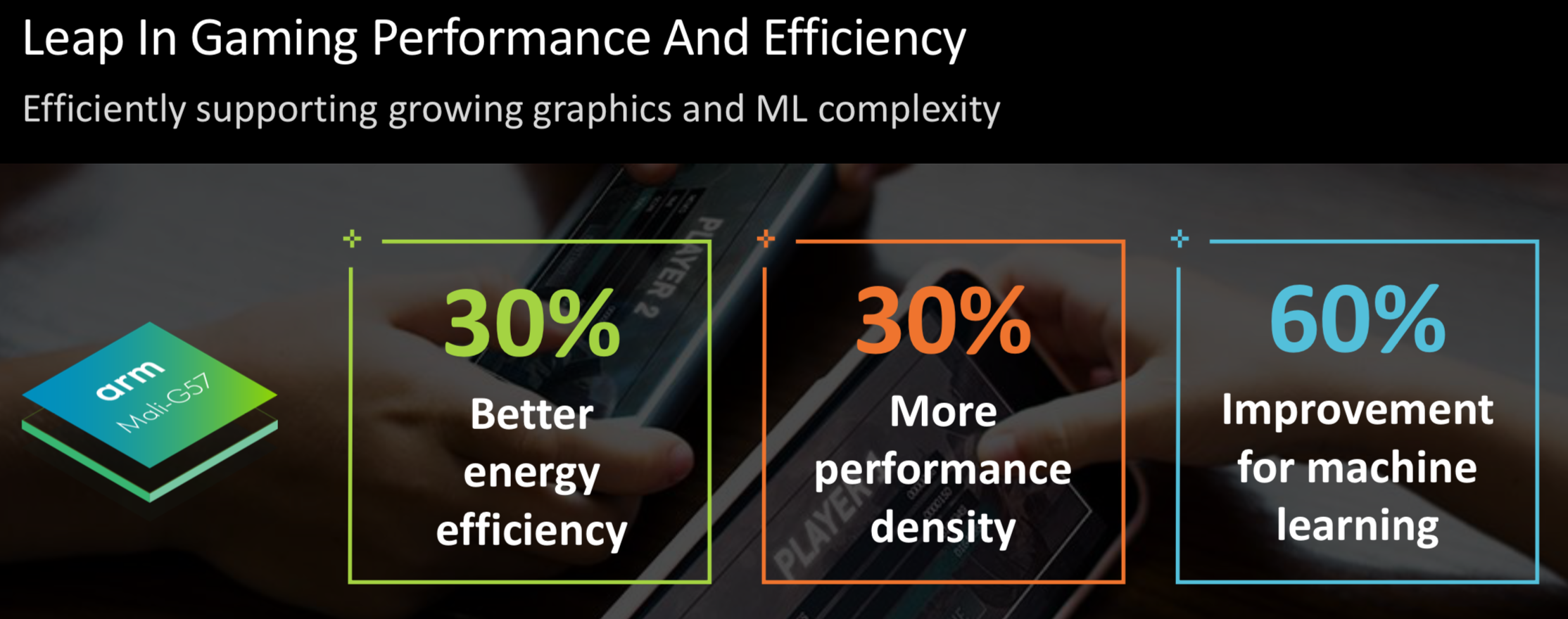
与Mali-G52相比,各种内容都能达到1.3倍的性能密度;
能效比提升30%,电池寿命更长;
针对VR提供注视点渲染支持,且设备ML性能提升60%,以便进行更复杂的XR实境应用。
Mali-D37关键功能包括:
单位面积效率高,DPU在支持全高清(Full HD)与2K分辨率的组态下,16nm制程的面积将小于1 mm2;
通过减少GPU核心显示工作以及包括MMU-600等内存管理功能,系统电力最高可节省30%;
从高阶的Mali-D71保留关键的显示功能,包括与Assertive Display 5结合使用后,可混合显示高动态对比(HDR)与标准动态对比(SDR)的合成内容。
对此,Arm市场营销副总裁Ian Smythe表示,这首先取决于是什么样的机器学习负载,如果是关键字识别,确实不需要专门的ML处理器,只需要在Cortex-M上运行推理引擎就可以,因为它本身就具有数据管理的能力,基本适用于一般的传感器系统。但如果是更加复杂的机器学习,就要考虑工作负载的卸载问题了,具体包括硬件方面的成本,以及编程工具的工作量等等。

Arm建议从系统级别出发进行选择,以达到降低功耗、减小芯片面积、提高效率、优化总体设计的目的。以图形处理任务为例,如果用GPU,它在执行任务时会多次访问内存,可能需要强制缩小像素,降低清晰度;但用DPU执行同样的任务,它会在完成任务后直接把数据发给GPU,这时GPU就无需再去访问内存,相当于把GPU的一些工作负载分配给DPU,从而能够节约能耗和带宽。
Arm ML事业群商业与营销副总裁Dennis Laudick强调,Arm的NPU属于通用型。其实现在市场上大部分还是用Arm的CPU来处理ML工作负载,新发布的NPU是对其CPU ML性能的进一步提升,以便提供更多的IP选择。
现在的市场时机之下,Dennis Laudick认为,选择通用型处理器非常合适。就ML处理能力来看,用户对于CPU和GPU的需求还是非常高的,同时也有一些针对NPU的需求。由于AI本身还处于非常初期的阶段,选择通用处理器是比较安全的做法,即便算法迭代非常快,硬件还能够有2到3年的生命周期。

探究Arm这一举动背后的含义。
首先,当我们真正进入IoT时代时,不论传感器还是其他IoT设备都是万亿级的,客户规模及类型都将指数级增长,Arm需要授予客户能力,让他们能够根据实际需求实现自己指令集的定制化。
其次,可以说市场上一些开源指令集的出现对Arm构成了一定的竞争,Arm虽然能够提供非常全面的指令集产品,但是定制化需求确实越来越强劲。
去年11月,Facebook就曾发表白皮书,要求其开发人员在移动设备上针对Cortex A53 SoC进行优化。由于不同SoC对AI加速的实施方法不同,如果是原生的软件,可以利用SoC的加速能力;但如果是第三方软件(Facebook就属于第三方应用),就很难用到这些SoC的加速能力。
类似的案例,使Arm逐渐认识到了有定制需求的市场规模。通过框架开源,能够允许第三方开发人员接入,在标准的编译访问、工具访问的情况下,只需一次开发就可以获得Arm全系列的硬件产品性能。
此外,Arm也宣布延伸与Unity的合作伙伴关系。目前,有七成VR内容的开发都在Unity工具链中发生,双方将进一步优化基于Arm的SoC、CPU和GPU的性能,使开发人员得以将更多的时间用于创造全新的、沉浸式的内容。

全面计算(Total Compute)的理念被应用到Arm的每一个计算要素,包括CPU、NPU、GPU、DPU,以及互连或系统IP等。初衷在于确保它们是由实际体验所驱动,同时针对解决未来工作负荷的复杂运算挑战进行了优化。
硬件方面普及性不断提升,软件开始一定的开源尝试——这是Arm对于未来计算架构思考方式的重大转变。
在介绍Total Compute理念的时候,Ian Smythe提到了三个因素:性能、可访问、安全。前两个因素主要来自于软硬件的协同发展,而第三个因素——安全,是一切设想得以实现的基础。
Total Compute的安全性基于三个层次:
第一个层级是最基本的平台级安全,涉及标准以及规则,做到合规;
第二个是处理级的安全,指的是处理器运行的软件线程,主要防止通过某一个处理通道发起的攻击,属于深度防御;
第三个是应用级的安全,即虚拟机在云端的应用安全。
在最基本层次的安全方面,Arm将会加强基本安全级别如身份验证、鉴权等工作,同时还有防止分支攻击的方式。此外还有一种安全架构叫做内存时间延展,Arm发现70%的操作系统崩溃或错误,都是因为内存不当的访问造成的,于是和Google共同合作了Arm V8.5,来防止类似的情况发生。
针对应用层安全,Arm与微软、谷歌等公司联合进行了安全架构方面的研究,主要通过编程方式的改变来防范现在比较流行的攻击方式。与剑桥大学共同开发的Prototype能力架构,能够将每个应用独立隔离,如果黑客攻破其中一个应用,其他不受影响。
Arm正在将创新的安全功能整合到Total Compute内,以迎合客户的各种需求。

这种异构计算需求能否为Arm及其生态发展带来新一轮增长点?Arm生态中的合作伙伴能否从中获得巨大的商业价值?市场还需要持续的发酵和验证。不过,观察他们是如何提升生态系统的高度,找到长久盛放的办法,可以从中得到一些答案。

一直以来,大量的数据从边缘流向云端,但随着数据和设备的数量呈指数型增长,把所有数据都放到云端处理变得越来越不现实,更不用说安全和成本效益。
机器学习(Machine Learning,ML)向“边缘”转移成为必然趋势,它将助力AI在更大范围的普及,推进更为多元化的应用。从整体架构来看,只有提升边缘的智能性,才能解决带宽、功耗、成本、延时、可靠性和安全性等多方面问题。
持续拓宽ML处理器IP覆盖
在日前的Arm Tech Symposia 2019北京站上,Arm宣布进一步扩充其IP组合。这些IP组合沿袭了Arm一直倡导的大小核理念,既有比较高端的配置(如Ethos-N57和Mali-G57),也有入门级的产品(如Ethos-N37和Mali-D37),目的在于将软硬件充分结合,并充分发挥生态系统的力量来提升主流设备的使用体验。由于消费级设备越来越智能化,通过专属的ML处理器提供额外的AI性能与效率非常有必要。
自从推出Cortex-A73后,Arm便逐步且逐代地提升性能,大幅拓宽针对ML的CPU覆盖。计算能力不断被推升至全新水平,直到最新一代Matterhorn内核,预计其计算性能将提升10倍。
当CPU和GPU面对边缘计算更密集计算、更复杂任务、更高效需求等显现出一定的匮乏时,NPU将派上用场。
继定位于高端设备的Ethos-N77发布后,此次,Ethos NPU家族又添Ethos-N57与Ethos-N37两位新成员,将ML处理器延伸到主流市场。全新的Ethos对成本与电池寿命最为敏感的设计进行了优化,可以为日常生活设备带来优质的AI体验。
Ethos-N57与Ethos-N37的设计理念包括:
针对Int8与Int16数据类型的支持性进行优化;
先进的数据管理技术,以减少数据的移动与相关的耗电;
通过如创新的Winograd技术的落地,使性能比其他NPU提升超过200%。
Ethos-N57旨在提供平衡的ML性能与功耗效率,能够针对每秒2兆次运算次数的性能范围进行优化;Ethos-N37则为了提供面积最小的ML推理处理器(小于1平方毫米)而设计,能够针对每秒1兆次运算次数的性能范围进行优化。
Arm在ML内核方面主要关注数据管理,在设计中更多地注入了智能数据管理的功能和理念,例如数据敏感型的压缩技术、高密度剪枝和稀疏功能等。
Mali-G57:为主流市场带来智能与沉浸式体验的GPU
同时推出的还有将优质智能与沉浸式体验带到主流市场的Mali-G57,是第一个基于Valhall架构的主流GPU。主要针对移动市场中最大的一部分应用,包括高保真游戏、媲美电玩主机的移动设备图型效果、DTV的4K/8K用户接口,以及更为复杂的虚拟现实和增强现实的负荷等。Mali-G57关键功能包括:
与Mali-G52相比,各种内容都能达到1.3倍的性能密度;
能效比提升30%,电池寿命更长;
针对VR提供注视点渲染支持,且设备ML性能提升60%,以便进行更复杂的XR实境应用。
Mali-D37:Arm单位面积效率最高的处理器
Mali-D37是一个在最小的可能面积上包含丰富显示与性能的DPU。对于终端用户而言,这意味着当面积成为首要考虑,在例如入门级智能手机、平板电脑与分辨率在2K以内的小显示屏等成本较低的设备上,会有更佳的视觉效果与性能。Mali-D37关键功能包括:
单位面积效率高,DPU在支持全高清(Full HD)与2K分辨率的组态下,16nm制程的面积将小于1 mm2;
通过减少GPU核心显示工作以及包括MMU-600等内存管理功能,系统电力最高可节省30%;
从高阶的Mali-D71保留关键的显示功能,包括与Assertive Display 5结合使用后,可混合显示高动态对比(HDR)与标准动态对比(SDR)的合成内容。
ML选择通用还是专用处理器?
是否一定需要专用的ML处理器?能否通过跨IP组合设计,或是对加速器进行优化,从而达到同样的或类似的性能?对此,Arm市场营销副总裁Ian Smythe表示,这首先取决于是什么样的机器学习负载,如果是关键字识别,确实不需要专门的ML处理器,只需要在Cortex-M上运行推理引擎就可以,因为它本身就具有数据管理的能力,基本适用于一般的传感器系统。但如果是更加复杂的机器学习,就要考虑工作负载的卸载问题了,具体包括硬件方面的成本,以及编程工具的工作量等等。
Arm建议从系统级别出发进行选择,以达到降低功耗、减小芯片面积、提高效率、优化总体设计的目的。以图形处理任务为例,如果用GPU,它在执行任务时会多次访问内存,可能需要强制缩小像素,降低清晰度;但用DPU执行同样的任务,它会在完成任务后直接把数据发给GPU,这时GPU就无需再去访问内存,相当于把GPU的一些工作负载分配给DPU,从而能够节约能耗和带宽。
Arm ML事业群商业与营销副总裁Dennis Laudick强调,Arm的NPU属于通用型。其实现在市场上大部分还是用Arm的CPU来处理ML工作负载,新发布的NPU是对其CPU ML性能的进一步提升,以便提供更多的IP选择。
现在的市场时机之下,Dennis Laudick认为,选择通用型处理器非常合适。就ML处理能力来看,用户对于CPU和GPU的需求还是非常高的,同时也有一些针对NPU的需求。由于AI本身还处于非常初期的阶段,选择通用处理器是比较安全的做法,即便算法迭代非常快,硬件还能够有2到3年的生命周期。
开源Arm NN——标准化前提下的定制化
此次Arm的一个重要举措还有开源类神经网络开发工具包 Arm NN,允许第三方合作伙伴进行定制化——Arm称之为“允许标准化前提下的定制化”。探究Arm这一举动背后的含义。
首先,当我们真正进入IoT时代时,不论传感器还是其他IoT设备都是万亿级的,客户规模及类型都将指数级增长,Arm需要授予客户能力,让他们能够根据实际需求实现自己指令集的定制化。
其次,可以说市场上一些开源指令集的出现对Arm构成了一定的竞争,Arm虽然能够提供非常全面的指令集产品,但是定制化需求确实越来越强劲。
去年11月,Facebook就曾发表白皮书,要求其开发人员在移动设备上针对Cortex A53 SoC进行优化。由于不同SoC对AI加速的实施方法不同,如果是原生的软件,可以利用SoC的加速能力;但如果是第三方软件(Facebook就属于第三方应用),就很难用到这些SoC的加速能力。
类似的案例,使Arm逐渐认识到了有定制需求的市场规模。通过框架开源,能够允许第三方开发人员接入,在标准的编译访问、工具访问的情况下,只需一次开发就可以获得Arm全系列的硬件产品性能。
此外,Arm也宣布延伸与Unity的合作伙伴关系。目前,有七成VR内容的开发都在Unity工具链中发生,双方将进一步优化基于Arm的SoC、CPU和GPU的性能,使开发人员得以将更多的时间用于创造全新的、沉浸式的内容。
Total Compute理念应对未来复杂边缘计算
应对未来复杂边缘计算的趋势,不难发现,Arm的关注焦点正在从单一的产品演进转化为以应用场景与体验为导向的系统解决方案。全面计算(Total Compute)的理念被应用到Arm的每一个计算要素,包括CPU、NPU、GPU、DPU,以及互连或系统IP等。初衷在于确保它们是由实际体验所驱动,同时针对解决未来工作负荷的复杂运算挑战进行了优化。
硬件方面普及性不断提升,软件开始一定的开源尝试——这是Arm对于未来计算架构思考方式的重大转变。
在介绍Total Compute理念的时候,Ian Smythe提到了三个因素:性能、可访问、安全。前两个因素主要来自于软硬件的协同发展,而第三个因素——安全,是一切设想得以实现的基础。
Total Compute的安全性基于三个层次:
第一个层级是最基本的平台级安全,涉及标准以及规则,做到合规;
第二个是处理级的安全,指的是处理器运行的软件线程,主要防止通过某一个处理通道发起的攻击,属于深度防御;
第三个是应用级的安全,即虚拟机在云端的应用安全。
在最基本层次的安全方面,Arm将会加强基本安全级别如身份验证、鉴权等工作,同时还有防止分支攻击的方式。此外还有一种安全架构叫做内存时间延展,Arm发现70%的操作系统崩溃或错误,都是因为内存不当的访问造成的,于是和Google共同合作了Arm V8.5,来防止类似的情况发生。
针对应用层安全,Arm与微软、谷歌等公司联合进行了安全架构方面的研究,主要通过编程方式的改变来防范现在比较流行的攻击方式。与剑桥大学共同开发的Prototype能力架构,能够将每个应用独立隔离,如果黑客攻破其中一个应用,其他不受影响。
Arm正在将创新的安全功能整合到Total Compute内,以迎合客户的各种需求。
结语
未来,随着数据类型愈发多样,如大数据应用、分布式存储和部分边缘计算等对多核、高能效计算提出明确需求,单个设备的计算能力固然很重要,但已不再是唯一的关注点,整个系统的计算能力更应该被关注。这种异构计算需求能否为Arm及其生态发展带来新一轮增长点?Arm生态中的合作伙伴能否从中获得巨大的商业价值?市场还需要持续的发酵和验证。不过,观察他们是如何提升生态系统的高度,找到长久盛放的办法,可以从中得到一些答案。
阅读下一篇
OPPO加紧自研芯片 未来将用在商品中
OPPO加紧自研芯片 未来将用在商品中-目前,拥有芯片设计研发能力的手机厂商屈指可数。此前有消息,继华为、小米之后,国产手机厂商OPPO也在自研芯片。
返回链料网首页